
L'IA occupe les gros titres quotidiennement: nouveaux modèles, partenariats inédits, produits innovants. Alors que ChatGPT fête ses trois ans, le paysage de l'intelligence artificielle est devenu un labyrinthe où les mêmes acteurs se font concurrence sur plusieurs fronts simultanément. Alphabet affronte Nvidia sur le marché des puces, tandis que Gemini rivalise avec ChatGPT comme modèle de langage. Mais comment ces différentes batailles s'articulent-elles et quel est le fil conducteur de cette guerre technologique?
Explication des processeurs CPU, GPU et TPU
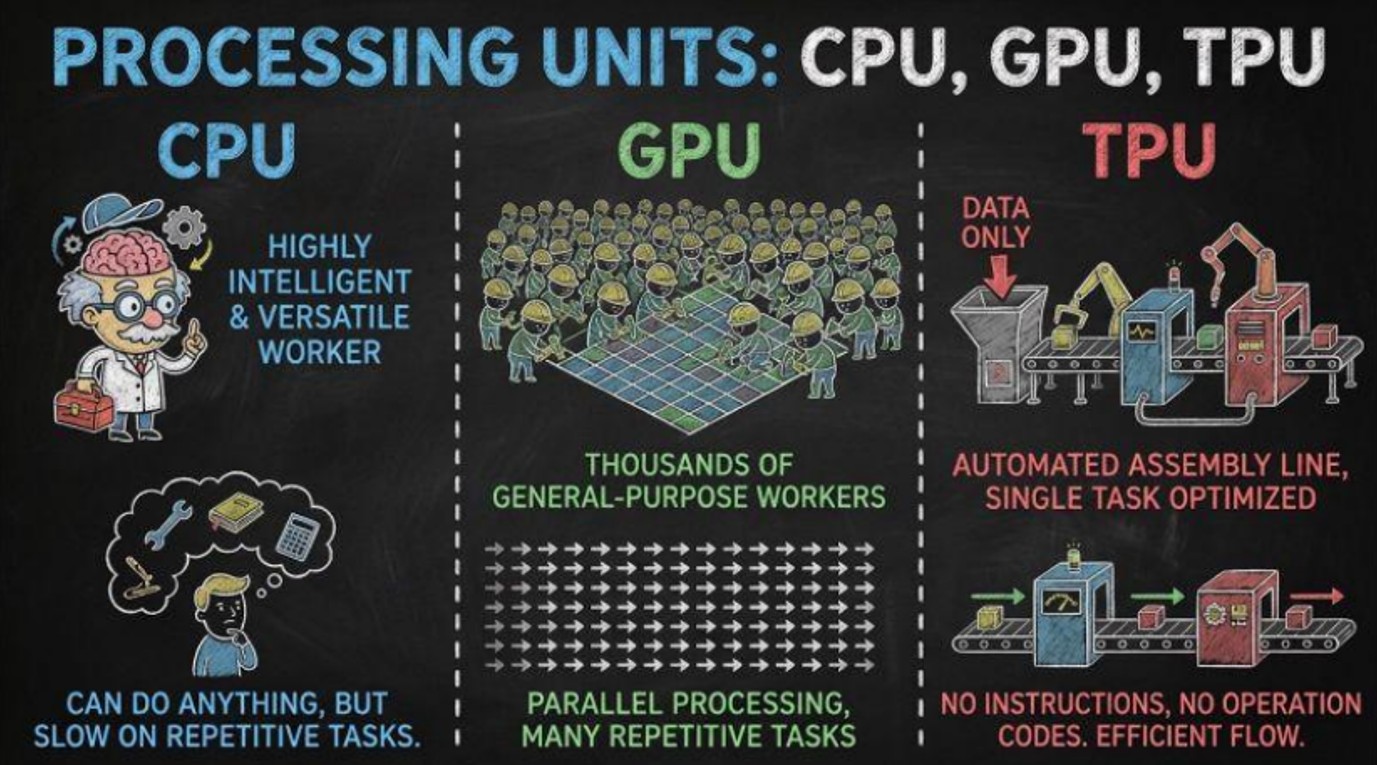
Les CPU constituent le cœur des ordinateurs depuis les débuts de l'informatique moderne. Encore aujourd'hui, chaque ordinateur fonctionne avec un CPU. C'est le processeur principal et il agit comme le «cerveau polyvalent» de l'ordinateur. Sans lui, votre ordinateur ne pourrait même pas démarrer. Cependant, ces puces ont été conçues pour la flexibilité et non pour des calculs répétitifs. Ainsi, dans les années 1990, alors que les jeux vidéo devenaient de plus en plus réalistes, les ordinateurs avaient besoin de puces capables de traiter des millions de pixels simultanément plutôt qu'un à la fois. C'est ce qui a conduit aux unités de traitement graphique (GPU). Un GPU, c’est essentiellement des milliers de petites unités de calcul plus simples qui travaillent en parallèle. Tandis qu'un CPU colorie les pixels un par un, un GPU les colorie tous en même temps. La plupart des ordinateurs aujourd'hui possèdent à la fois un CPU et un GPU. Et le plus grand producteur de GPU était Nvidia.
Puis est arrivée l'IA moderne. L'entraînement de grands réseaux neuronaux nécessite des quantités vertigineuses de calculs matriciels, et ces calculs ressemblent presque exactement à ce que les GPU étaient déjà conçus pour faire pour les graphiques 3D. Nvidia a capitalisé sur cela en adaptant les GPU pour les centres de données, bien plus grands et puissants que ceux des ordinateurs portables, et a gagné une part de marché énorme très rapidement. Les GPU, cependant, restaient des puces graphiques polyvalentes, et non des puces IA conçues spécifiquement à cet effet. En 2015, Google a introduit l'unité de traitement tensoriel (TPU), conçue spécifiquement pour les opérations utilisées dans les réseaux neuronaux. En d'autres termes, le TPU est un ASIC (circuit intégré spécifique à une application), une puce personnalisée pour un usage particulier, plutôt que destinée à un usage général. Cette spécialisation a permis aux TPU d'offrir un rapport coût-efficacité supérieur, une meilleure efficacité énergétique et un débit élevé à grande échelle.
Enfin, un autre type de puce est l'unité de traitement neuronal (NPU). Elles fonctionnent directement sur l'appareil (par exemple les smartphones), en se concentrant sur l'efficacité énergétique et le traitement IA en temps réel. Elle ne concurrence pas les GPU et TPU, car elle est loin d'être idéale pour l'entraînement de modèles IA à grande échelle et dispose d'une puissance de calcul inférieure. Cependant, comme elles sont optimisées pour les applications IA à faible consommation d'énergie, elles sont principalement déployées dans des applications telles que la reconnaissance d'images et la reconnaissance vocale en temps réel.
Source: Leon Zhu & SemiVision sur X
Mais si les TPU sont meilleurs que les GPU pour l'entraînement et l'inférence, pourquoi tous les LLM n'utilisent-ils pas des TPU?
Parce que l'histoire a enfermé le monde de l'IA dans les GPU bien avant l'arrivée des TPU. Voyez les choses ainsi: au moment où Google a inventé le TPU en 2015, le monde de l'apprentissage automatique (“Machine Learning”) avait déjà passé une décennie à tout construire, comme le code de recherche, les premières bibliothèques de réseaux neuronaux, les cours universitaires et l'infrastructure des entreprises, sur la base des GPU Nvidia. Et la raison n'était pas seulement que «les GPU sont bons». C'était CUDA, la plateforme de programmation propriétaire de Nvidia lancée en 2007.
CUDA permettait aux développeurs d'écrire du code exploitant directement la puissance parallèle des GPU. C'était stable, rapide, bien documenté et, surtout, cela fonctionnait partout, des PC de jeu aux centres de données géants. Cela a créé un effet d'entraînement. Plus de développeurs utilisaient CUDA, ce qui signifiait que plus d'outils et de bibliothèques étaient construits pour CUDA, ce qui poussait plus d'entreprises à acheter des GPU Nvidia, et enfin poussait encore plus de développeurs vers CUDA.
Au début des années 2010, tout l'écosystème était construit en supposant que les gens utilisaient des GPU Nvidia et CUDA. Les universités l'enseignaient. Les startups le déployaient. Les fournisseurs de cloud en remplissaient leurs entrepôts.
Quand Google a lancé les TPU, bien qu'ils soient puissants, surtout pour l’entraînement et l’inférence à grande echelle, ils étaient aussi beaucoup moins flexibles que les GPU en termes de types de modèles et d’opérations qu’ils pouvaient gérer. Et plus important encore, ils arrivaient en retard à une fête qu'Nvidia organisait depuis des années, et toute la communauté avait déjà construit sa maison sur CUDA.
De plus, Google ne vendait pas de TPU. Si vous vouliez les utiliser, vous deviez entraîner votre modèle sur Google Cloud. Pendant ce temps, les GPU Nvidia étaient partout: Amazon, Microsoft, Oracle, centres de données privés, clusters universitaires. Cette large disponibilité faisait des GPU le choix par défaut pour quiconque construisait un LLM.
Mais néanmoins, les meilleures performances des TPU et le souhait de moins dépendre d'une seule entreprise (dans ce cas, Nvidia) ont conduit les acteurs à commencer à intégrer les puces de Google dans leur chaîne de valeur. Anthropic a récemment signé un accord de plusieurs milliards de dollars avec Google, obtenant l'accès à jusqu'à un million de TPU. Leurs modèles fonctionneront désormais sur trois plateformes différentes: les GPU de Nvidia, les puces Trainium personnalisées d'Amazon (qui sont elles aussi des ASIC), et les TPU de Google. Meta serait également en pourparlers avec Alphabet pour investir des milliards de dollars dans les TPU de Google pour ses centres de données d'ici 2027. Cela aiderait l'entreprise à diversifier son approvisionnement en puces au-delà des GPU de Nvidia et AMD. Plus généralement, davantage d'entreprises cherchent à construire leurs propres ASIC. Par exemple, OpenAI a conclu un nouvel accord avec Broadcom (qui a aidé à construire les TPU de Google) pour créer ses propres ASIC à partir de 2026.
Deux camps dans l’IA
La bataille pour la suprématie en intelligence artificielle semble aujourd’hui s’être scindée en deux blocs concurrents. D’un côté, le «Complexe Google», articulé autour d’Alphabet et d’un vaste réseau de fournisseurs d’infrastructures (Broadcom, Celestica, Lumentum, TTM Technologies). De l’autre, le «Complexe OpenAI», centré sur OpenAI et soutenu par des partenaires tels que Microsoft, Nvidia, Oracle, SoftBank, AMD et CoreWeave. Microsoft assure à la fois le soutien financier et l’infrastructure cloud Azure sur laquelle OpenAI entraîne et déploie ses modèles. Nvidia et AMD fournissent les GPU et accélérateurs indispensables à cette puissance de calcul. CoreWeave, partiellement détenu par Nvidia, opère comme un fournisseur cloud haute performance spécialisé, mettant à disposition d’immenses clusters de GPU destinés à absorber une part du travail d’entraînement qu’Azure ne peut assumer seule. Oracle, quant à elle, a conclu des accords pluriannuels pour héberger les charges de travail d’OpenAI sur son propre cloud, élargissant l’empreinte de calcul de l’écosystème.
Pendant près de deux ans, toute proximité avec le «Complexe OpenAI» a été saluée par les marchés. Un nouveau contrat d’approvisionnement en puces avec Nvidia, une extension des capacités cloud chez Oracle ou encore un simple rapprochement stratégique avec OpenAI suffisait à déclencher des hausses marquées, tant les investisseurs anticipaient une croissance fulgurante de la demande en IA et des revenus associés.
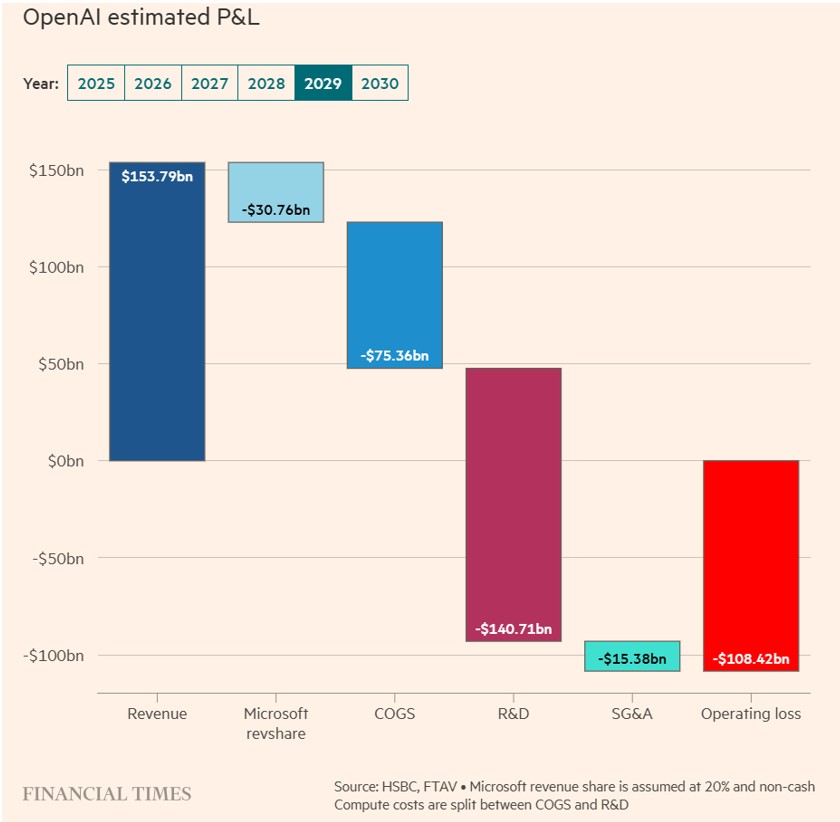
Cette dynamique s’est cependant inversée ces dernières semaines. Désormais, un lien étroit avec OpenAI est perçu comme un risque plutôt qu’un atout. SoftBank, qui détient environ 11 % du capital d’OpenAI, a chuté de près de 40 % en novembre. L’action Oracle, qui s’était envolée après l’annonce d’un accord d’infrastructure colossal à 300 milliards de dollars, voit désormais ses credit-default swaps s’écarter sensiblement, les investisseurs réévaluant le risque de construire des capacités massives pour un client dont la solidité financière apparaît nettement plus fragile qu’escompté. Même Microsoft, pourtant protégé par sa taille et sa diversification, n’a pas échappé aux pressions. HSBC estime désormais qu’OpenAI pourrait cumuler près de cinq-cents milliards de dollars de pertes opérationnelles d’ici 2030, une estimation qui soulève de sérieux doutes quant à la viabilité financière d’un écosystème déjà alourdi par des investissements colossaux, un recours accru à l’endettement et des valorisations élevées.
Source: Financial Times
À l’opposé, le Google Complex repose sur une discipline d’investissement remarquable, une infrastructure interne colossale et des marges solides. Sur la dernière année, Alphabet a généré 151,4 milliards de dollars de flux de trésorerie opérationnels, de quoi financer près de 78 milliards de dollars de dépenses d’investissement, rembourser environ 20 milliards de dollars de dette et distribuer près de 70 milliards de dollars aux actionnaires sous forme de rachats d’actions et de dividendes. Rares sont les entreprises engagées dans la course à l’IA capables d’atteindre un tel niveau de génération de trésorerie, combinant un free cash-flow robuste et une pression de bilan limitée, surtout comparées au «Complexe OpenAI». Cette solidité permet à Alphabet de déployer sans difficulté des modèles comme Gemini 3. En entraînant ce dernier exclusivement sur ses propres TPU, Alphabet réduit drastiquement ses coûts internes de calcul tout en posant les bases d’une activité Hardware stratégique.
Cette puissance financière et cette intégration verticale se reflètent désormais dans les performances du modèle. Gemini 3 s’est hissé au sommet des classements internationaux et est aujourd’hui considéré comme le modèle le plus avancé du marché. Dans le dernier classement LMArena, il arrive largement en tête des votes. Marc Benioff, CEO de Salesforce, n’a pas caché sa réaction après l’avoir testé: «J’ai utilisé ChatGPT tous les jours pendant trois ans. Deux heures avec Gemini 3, je ne reviendrai pas en arrière.»
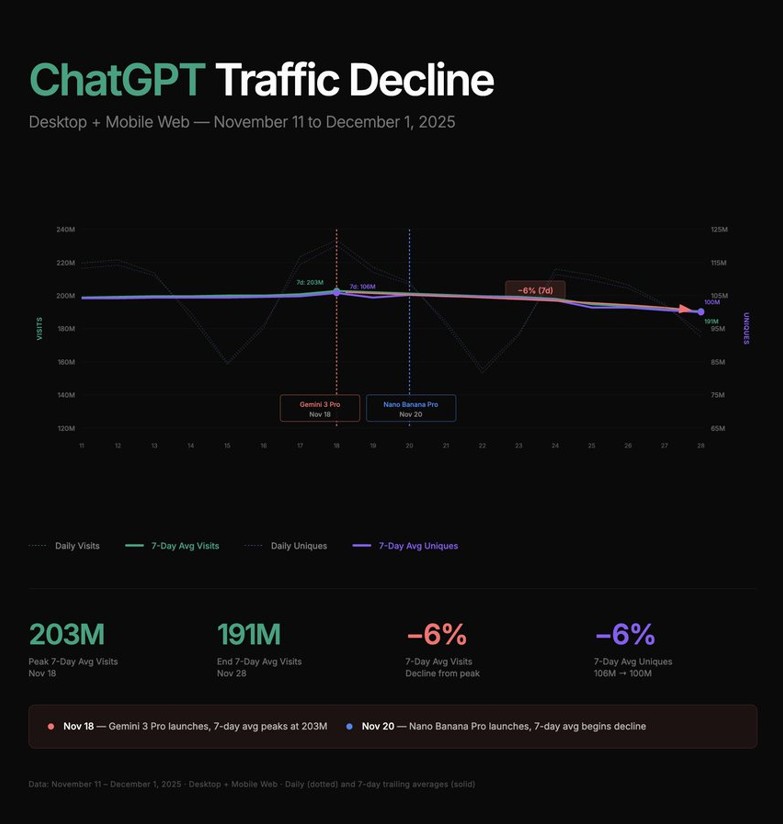
Ce choc de performance a exercé une pression tangible sur le «Complexe OpenAI». Sam Altman aurait diffusé une note interne de «code rouge» après le lancement de Gemini 3, reconnaissant la menace croissante posée non seulement par Google, mais aussi par Claude d’Anthropic. Les données SimilarWeb montrent que le trafic de ChatGPT a chuté d’environ 6 % dans les semaines suivant l’arrivée de Gemini 3, passant de 203 millions à 191 millions de visites quotidiennes.
Source: Deedy Das sur X
Conclusion
Nvidia demeure une puissance incontournable, et la demande pour ses GPU reste extrêmement élevée. Les nouvelles architectures Blackwell et Rubin pourraient même consolider sa position dès 2026. Toutefois, les grands acteurs du cloud développent désormais leurs propres puces, les marges se resserrent, et les investisseurs se montrent de plus en plus prudents face au levier financier et au surinvestissement qui entourent l’écosystème OpenAI. Le véritable atout défensif de Nvidia demeure son écosystème logiciel CUDA et sa domination dans les charges d’entraînement des modèles.
Il ne s’agit pas d’un jeu à somme nulle. Le marché de l’IA croît trop rapidement pour qu’il n’y ait qu’un seul gagnant. Deux pôles de gravité émergent aujourd’hui: Alphabet, avec son stack intégré, hautement efficient, porté par un Gemini en pleine ascension; et Nvidia, soutenue par un écosystème logiciel sans équivalent et un leadership affirmé dans l’entraînement.