
Comment exploiter au mieux les énormes quantités de données disponibles dans le secteur financier, et en tirer un rendement supplémentaire dans le domaine des actions?

L’ère numérique a généré des montagnes de données. L’International Data Corporation estime que le monde génère en deux jours plus de données que l’humanité dans son ensemble depuis le début de l’année 2003. Sur la plateforme de services financiers Bloomberg, plus de 10'000 rapports, actualités et histoires sur les réseaux sociaux sont publiés chaque jour pour les entreprises internationales. La révolution du big data ouvre de nouvelles perspectives, notamment dans l'industrie financière, qui est l'un des secteurs de l’économie mondiale disposant du plus grand volume de données.
Traditionnellement, les données des marchés financiers sont évaluées par des analystes et des gestionnaires de fonds, et les décisions de placement sont prises sur la base de l’intuition humaine. Mais compte tenu de l’augmentation exponentielle du volume des données, il devient de plus en plus difficile d’extraire les informations vraiment importantes des flux de données et d’identifier les facteurs de rendement permettant d’estimer l’évolution future des cours. La technologie du big data présente un grand potentiel dans le secteur financier, car les algorithmes informatiques se prêtent idéalement au traitement d’énormes volumes de données et à la reconnaissance ultra rapide de schémas dans les données.
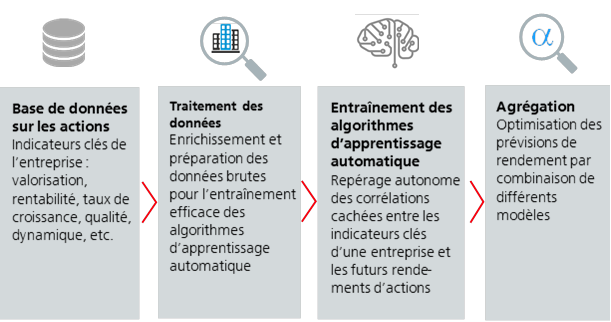
Les algorithmes d’apprentissage automatique (machine learning) les plus modernes sont capables d’explorer par eux-mêmes les données des marchés financiers et de repérer, sans intervention humaine, les corrélations cachées entre les indicateurs clés de l’entreprise et les rendements futurs. Ce processus peut être décomposé en quatre étapes:
- Base de données sur les actions
Tous les algorithmes d’apprentissage automatique reposent sur de volumineuses bases de données cumulées depuis des décennies sur toutes les actions du monde entier, et sur les données existantes sur les entreprises (valorisation, rentabilité, croissance, estimations des analystes, indicateurs de risques, dynamique, etc.). Plus un algorithme d’apprentissage automatique dispose de données pour son entraînement, plus les prévisions de rendement obtenues sont fiables et stables. - Préparation des données
Afin que les algorithmes puissent apprendre efficacement, les données brutes sont généralement enrichies d’indicateurs complémentaires et préparées. Cela peut se faire, par exemple, par la transformation ou la neutralisation des données. - Entraînement des algorithmes d’apprentissage automatique
A cette étape, l’algorithme apprend de lui-même à partir des données préparées. Il analyse quelle combinaison d’indicateurs clés d’entreprise génère des rendements supérieurs à la moyenne et détermine les particularités des actions à faible performance. Sur la base de ces résultats, il déduit automatiquement des modèles complexes qui permettent d’estimer l’évolution future des cours de toutes les actions à l’échellemondiale. De telles prévisions ne peuvent être le fruit de l’intelligence humaine, car il faudrait une armée d’analystes pour établir quotidiennement des prévisions de rendement pour des milliers d’actions. - Agrégation
Pour augmenter encore la probabilité de réalisation des prévisions de rendement, on combine différents algorithmes. Par exemple, il est possible d’associer des modèles spécialisés dans les prévisions à court terme (tactiques) et à long terme (stratégiques), ou spécialement conçus pour un marché haussier ou pour un marché baissier. L’agrégation dynamique de différents modèles de prévision permet d’obtenir des prévisions plus stables et plus fiables.
Les stratégies d’actions basées sur des algorithmes d’apprentissage automatique permettent d’identifier des sources d’alpha inaccessibles à l’homme en raison de leur grande complexité.
Ces stratégies s’adaptent rapidement et de manière dynamique à l’évolution des conditions du marché et peuvent générer des rendements supplémentaires, y compris dans des périodes difficiles, comme la bulle informatique, la crise financière ou la pandémie de coronavirus. Les rendements excédentaires établis lors de back-tests sont prometteurs et par ailleurs peu corrélés aux rendements des fonds en actions traditionnels, qui suivent une approche fondamentale. Par rapport aux stratégies de placement systématiques, qui ont généralement des orientations de style permanentes telles que Value ou Quality, les stratégies basées sur l’apprentissage automatique ne parient pas durablement sur un style particulier.
Jusqu’à présent, seuls quelques produits en actions accessibles au public font appel à des algorithmes d’apprentissage automatique pour la sélection des actions. A l’automne 2021, Swisscanto proposera une solution de placement innovante en émettant pour la première fois des certificats Artificial Intelligence Equity dont le processus de sélection reposera entièrement sur l’intelligence artificielle. Grâce à cette innovation, tous les investisseurs auront accès à des sources d’alpha jusqu’à présent ignorées.